

摘要:着智能交通系统的快速发展,车牌识别技术在停车场管理、交通监控等领域发挥着重要作用。
项目概览
项目简介
本文设计并实现了一种基于支持向量机(SVM)和形态学处理的车牌识别系统。系统采用HSV颜色空间进行车牌定位,利用形态学操作进行图像预处理和字符分割,通过训练好的SVM分类器实现车牌字符识别。
实验结果表明,该系统对蓝牌车辆具有较高的识别准确率,平均识别时间约为0.1秒,能够满足实时性要求。系统采用PyQt5开发了友好的图形用户界面,便于实际应用和演示。
系统架构
本系统采用分层架构设计,包括图像采集层、图像预处理层(HSV颜色空间转换与形态学处理)、车牌定位层(轮廓检测与区域筛选)、字符分割层(投影法分割)、字符识别层(SVM分类器)和用户交互层(PyQt5图形界面),各模块协同工作完成从图像输入到车牌号输出的完整流程。
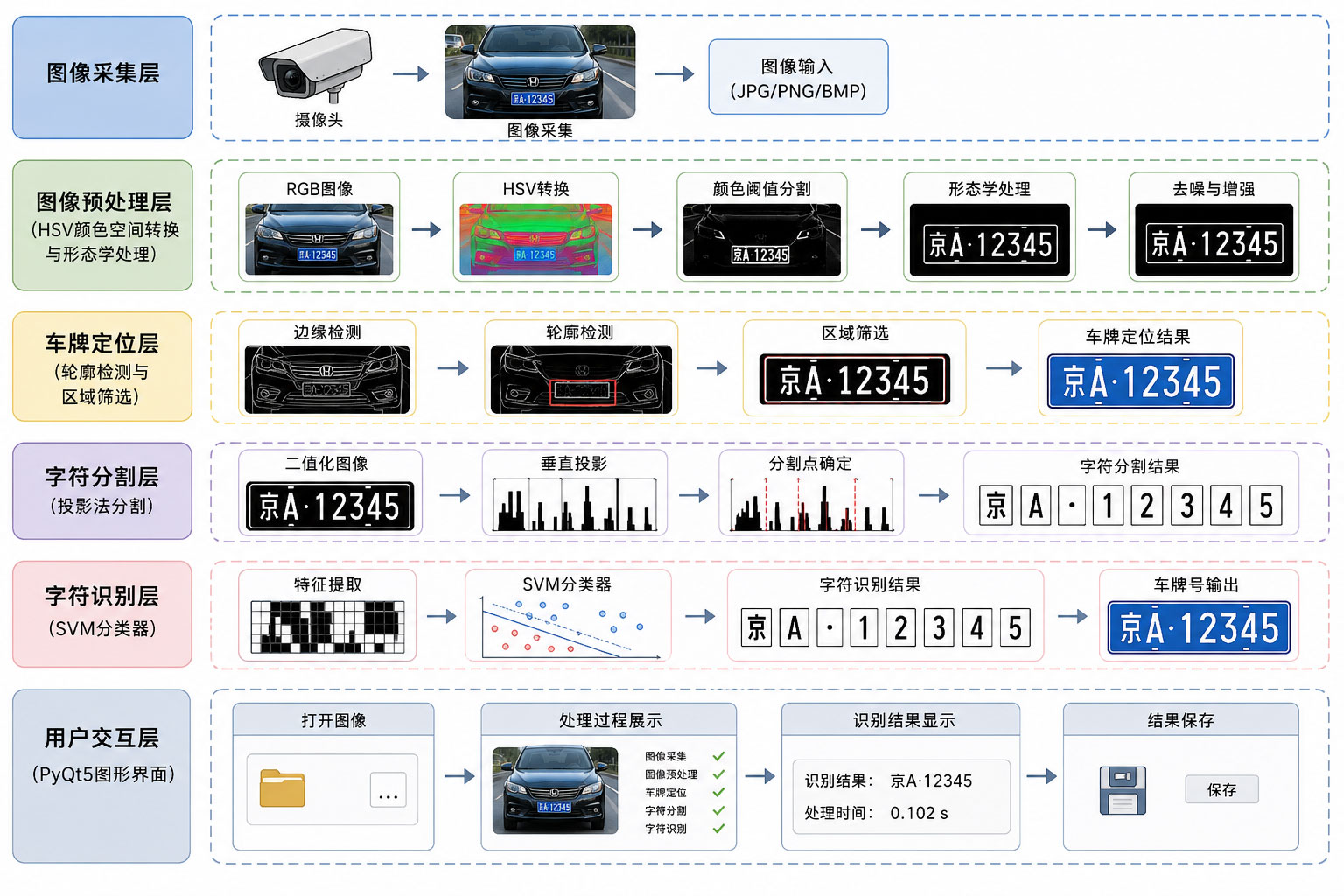
图1 系统架构图
技术创新
创新点1:基于HSV颜色空间的自适应车牌定位算法
采用HSV颜色空间替代传统RGB空间进行车牌定位,通过设定蓝色车牌的色调、饱和度和亮度阈值范围,有效降低光照变化对定位精度的影响,提高了复杂场景下的车牌检测准确率。
创新点2:多重形态学操作与轮廓筛选相结合的车牌提取策略
提出了一种结合闭运算、开运算等多重形态学操作与面积、长宽比、矩形度等多特征约束的车牌候选区域筛选方法,有效抑制了背景干扰,提高了车牌定位的鲁棒性。。
创新点3:基于SVM的中文字符与字母数字分类识别框架
设计了双分类器识别架构,分别训练中文省份字符分类器和字母数字分类器,针对车牌首字符和后续字符的不同特点进行专门优化,提高了整体识别准确率和系统的实用性。
数据集构建和训练
数据集构建
本系统的训练数据集包含两部分:字母数字数据集和中文省份简称数据集。字母数字数据集包含0-9共10个数字和A-Z(去除I和O避免混淆)共24个字母,总计34个类别,每个类别收集约400张不同字体、大小、角度的字符图片,共13,163张样本;中文省份数据集包含31个省份简称(如京、沪、粤等),每个省份收集约100张不同书写风格的字符图片,共3,232张样本。所有样本图片统一调整为20×20像素灰度图像,并进行归一化处理后作为SVM分类器的训练数据,确保模型对不同拍摄条件下的车牌字符具有良好的泛化能力。
数据集训练
本系统使用train.py脚本对数据集进行训练,分别训练字母数字识别模型和中文省份识别模型。训练时将所有样本图片统一处理为20×20像素灰度图像,展平为400维特征向量并归一化,采用RBF核函数的SVM分类器进行训练,通过交叉验证选择最优参数C和gamma。字母数字模型基于13,163张样本训练34个类别,中文模型基于3,232张样本训练31个省份类别,训练完成后分别保存为svm_model.pkl和svm_chinese.pkl,供车牌识别系统调用实现字符分类。
快速开始
安装依赖后运行python gui_optimized.py启动图形界面,点击”选择图片”选择车牌图像,再点击”开始识别”即可自动完成车牌定位与字符识别,识别结果将显示在界面右侧并可通过”保存结果”按钮导出。
环境要求
本系统需要Python 3.6及以上版本,依赖库包括OpenCV 4.x、PyQt5 5.15、scikit-learn、numpy等,建议在Windows/Linux/macOS系统上运行,通过pip install -r requirements.txt一键安装所有依赖。
运行展示
运行gui.py
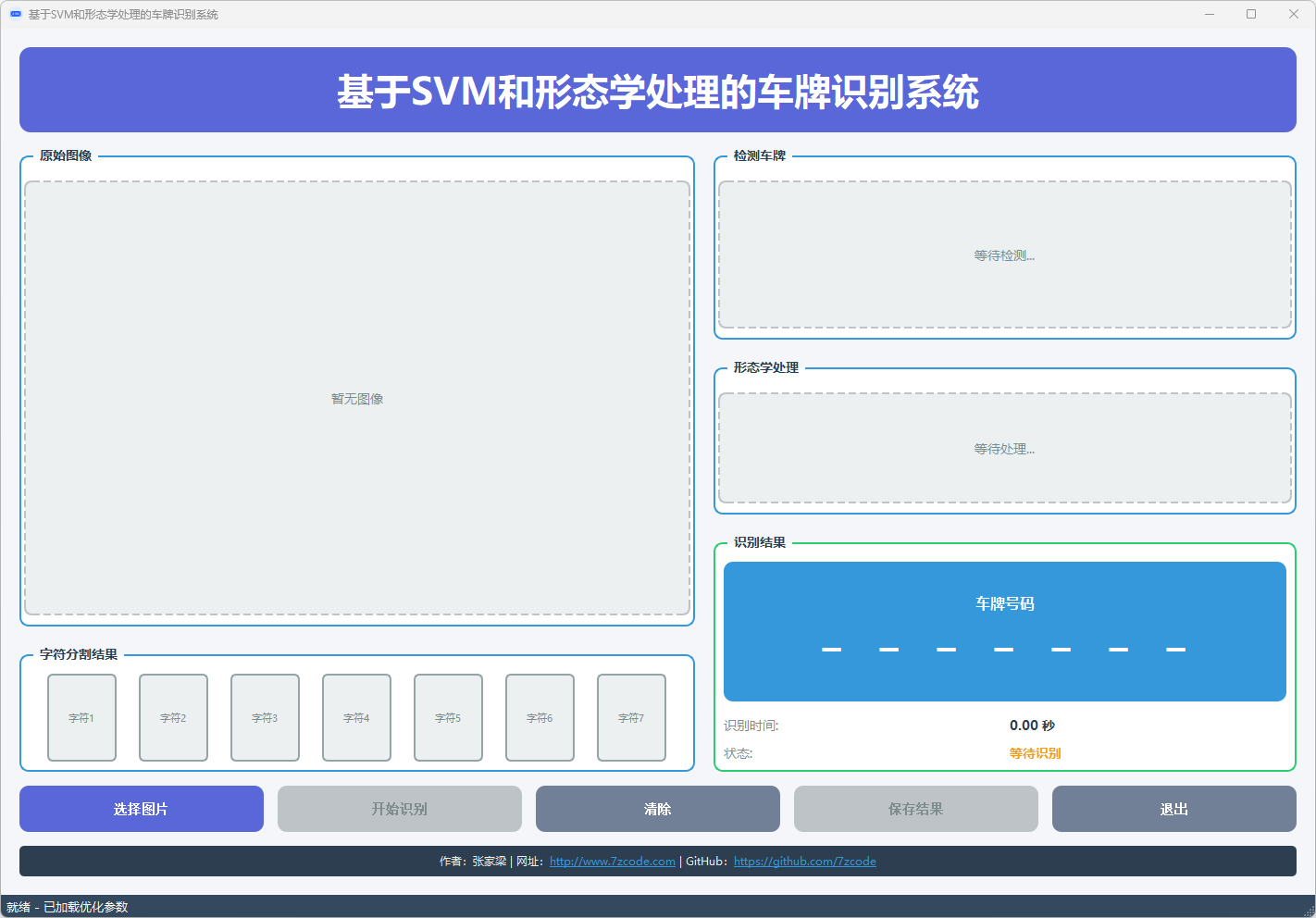
图2 系统主界面
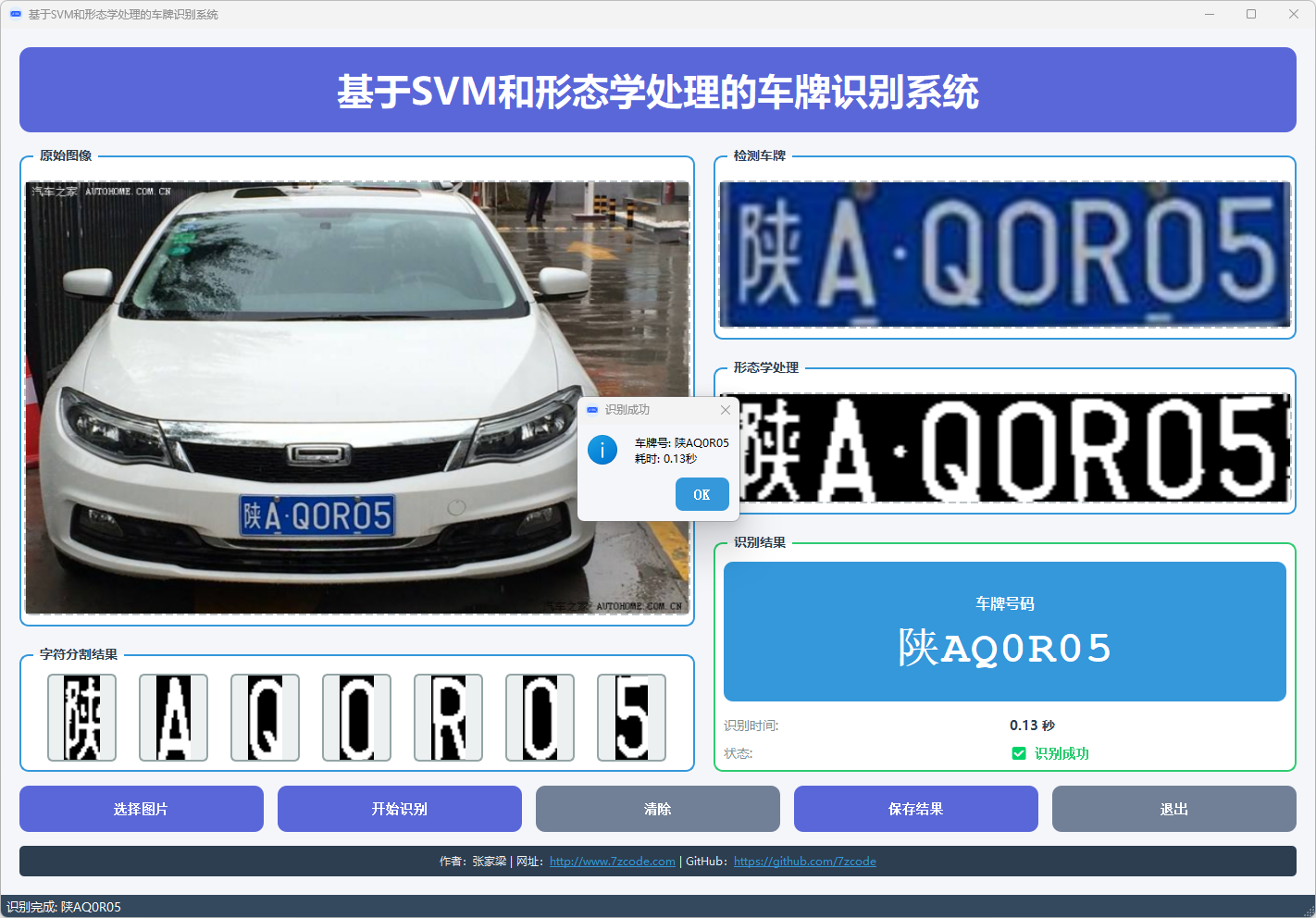
图3 车牌识别结果
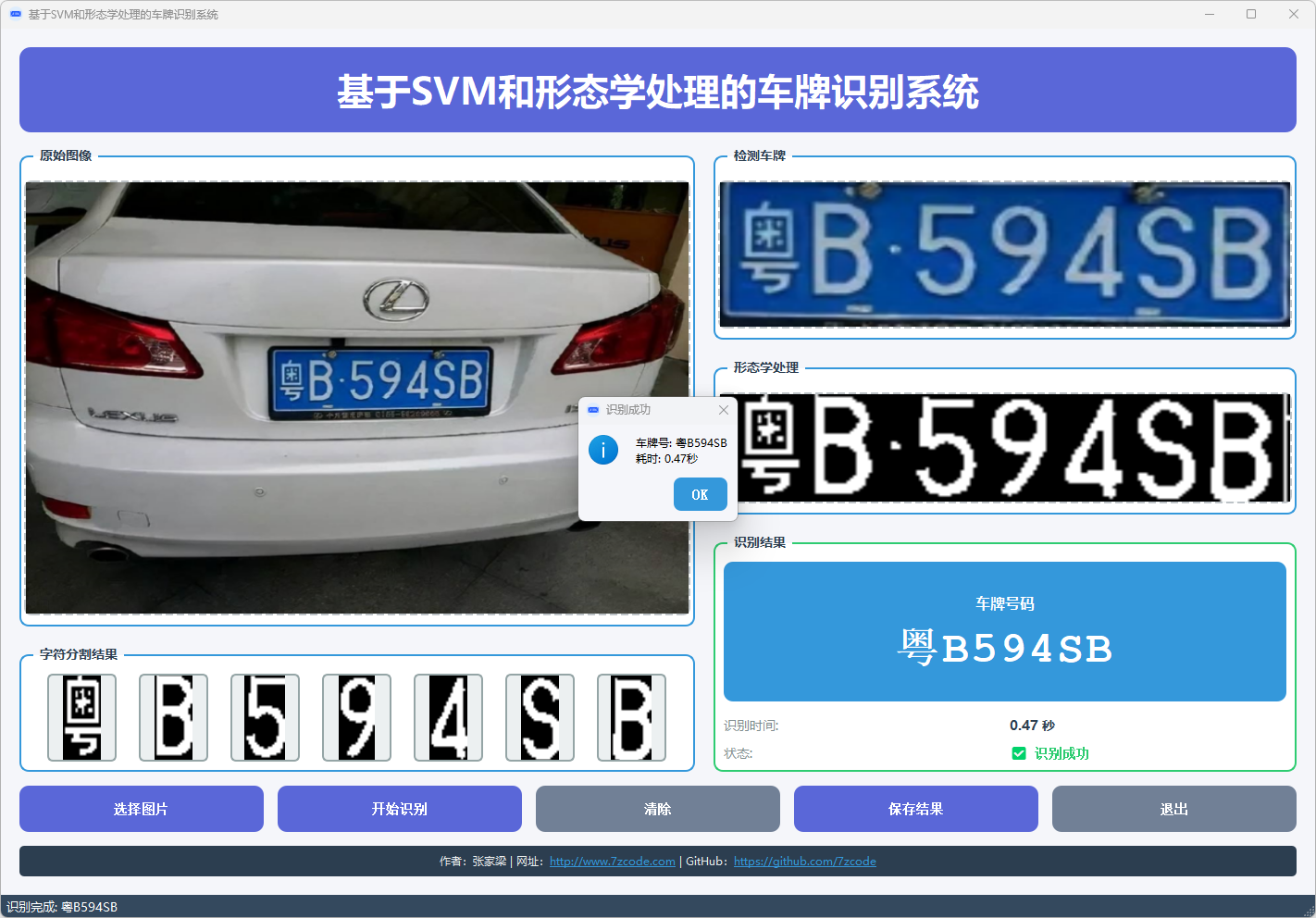
图4 车牌识别结果
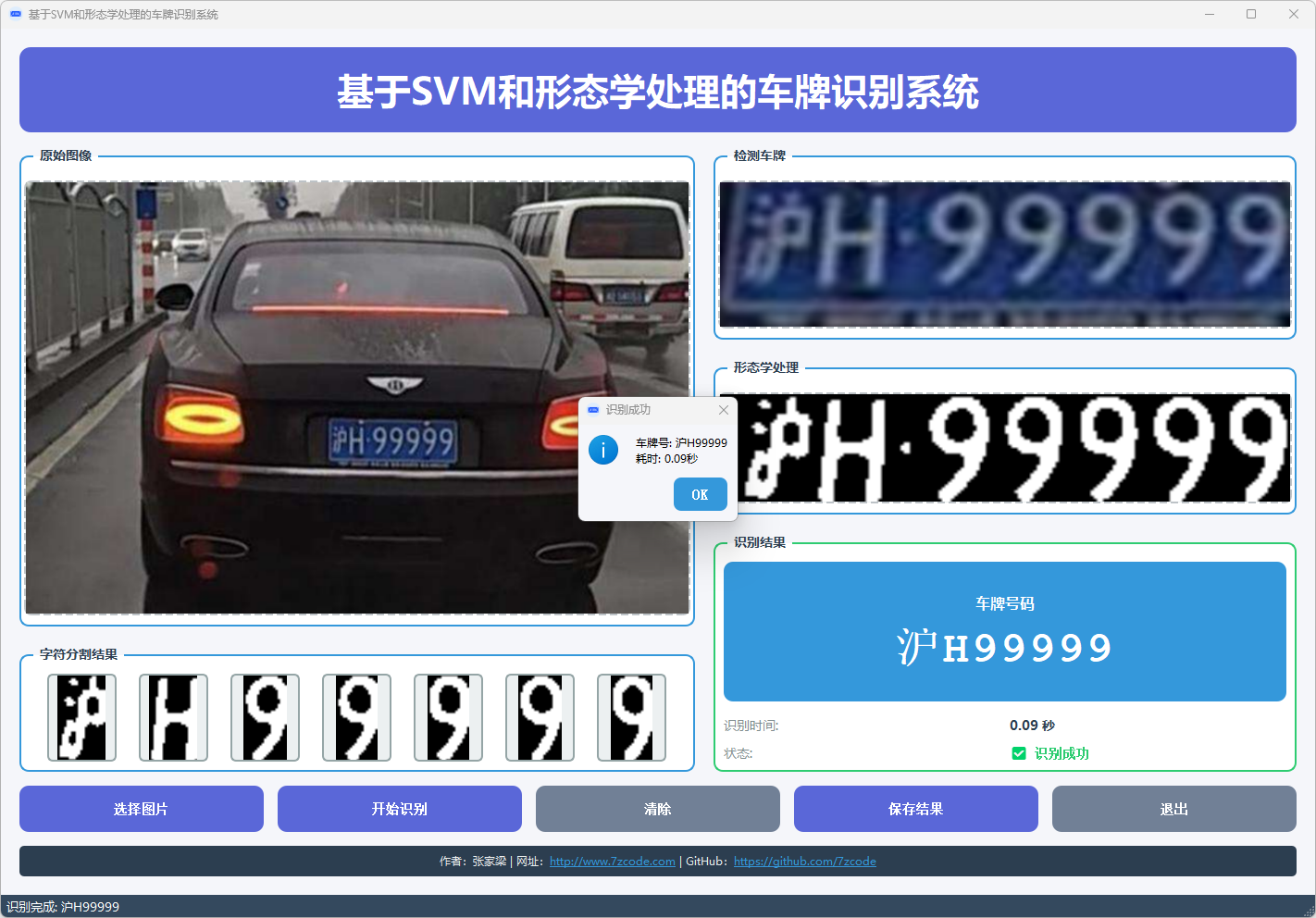
图5 车牌识别结果
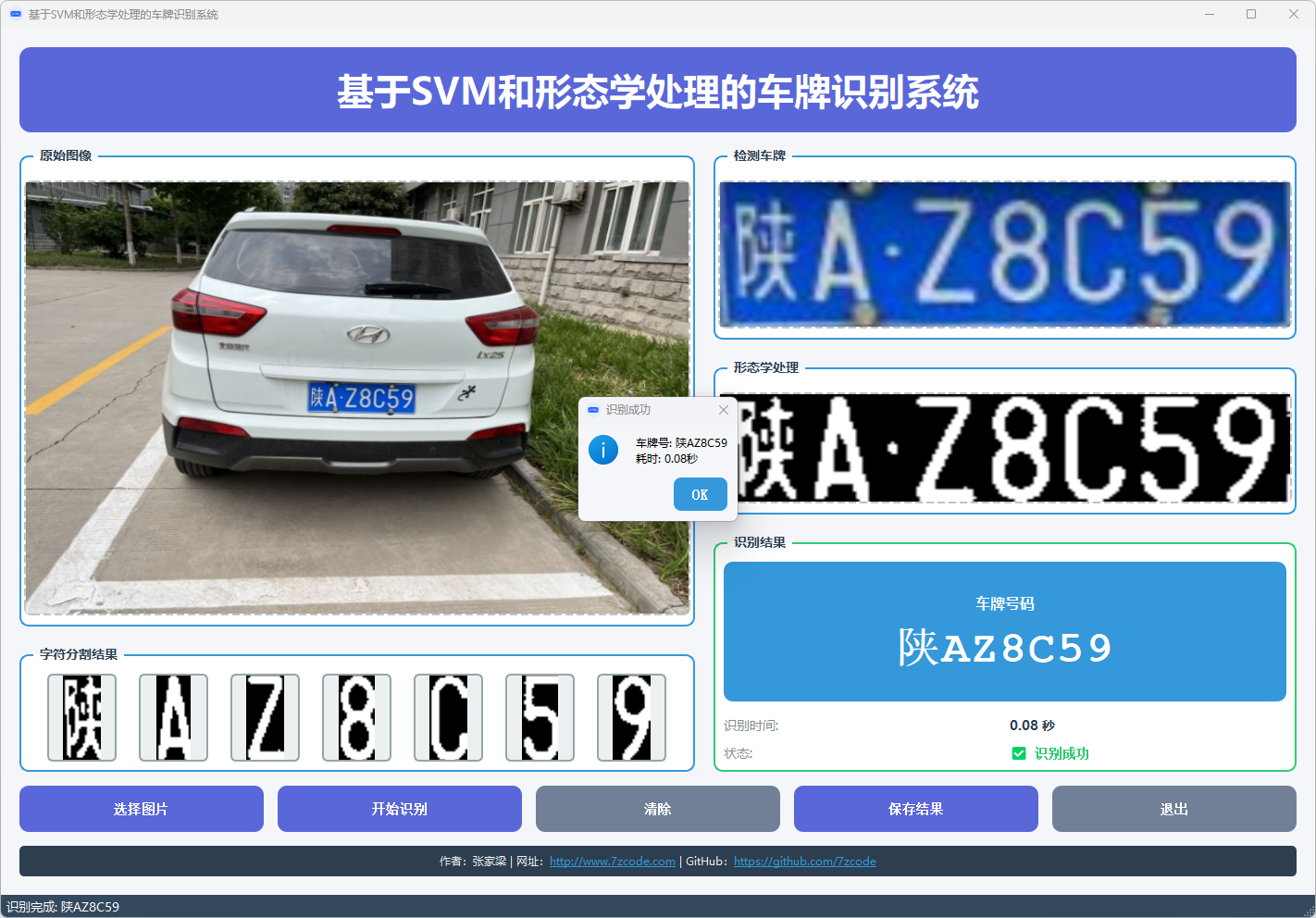
图6 车牌识别结果
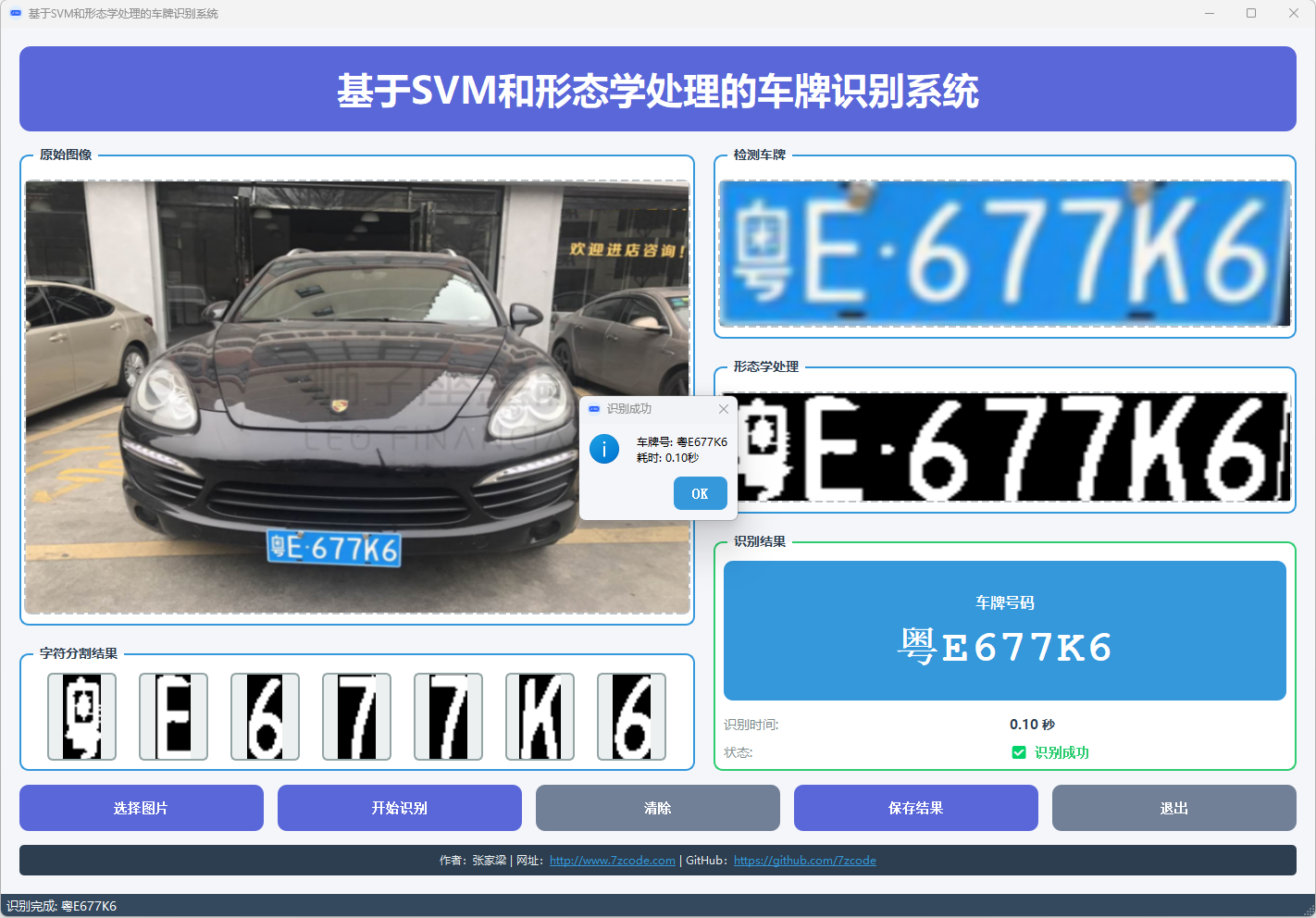
图7 车牌识别结果
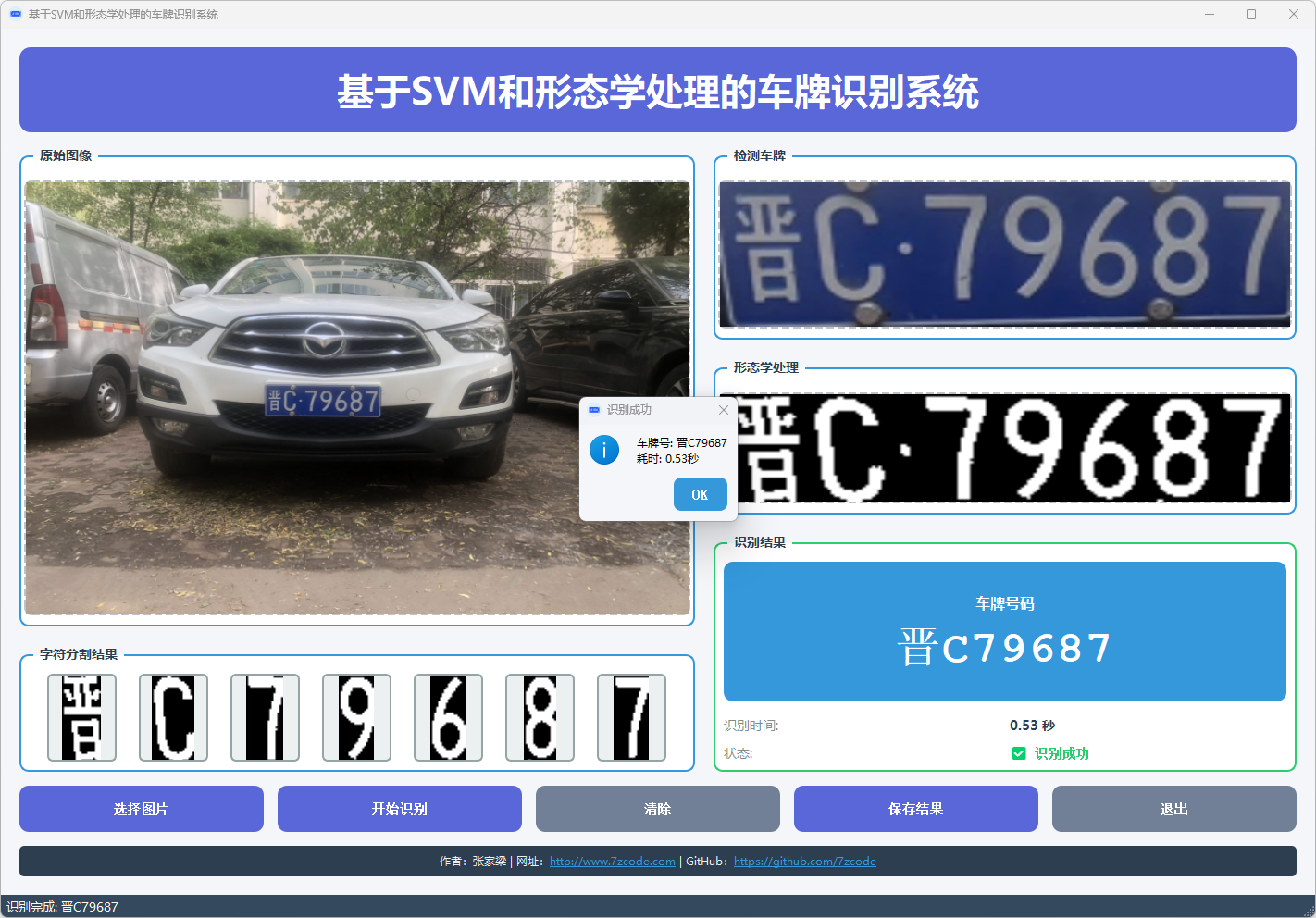
图8 车牌识别结果
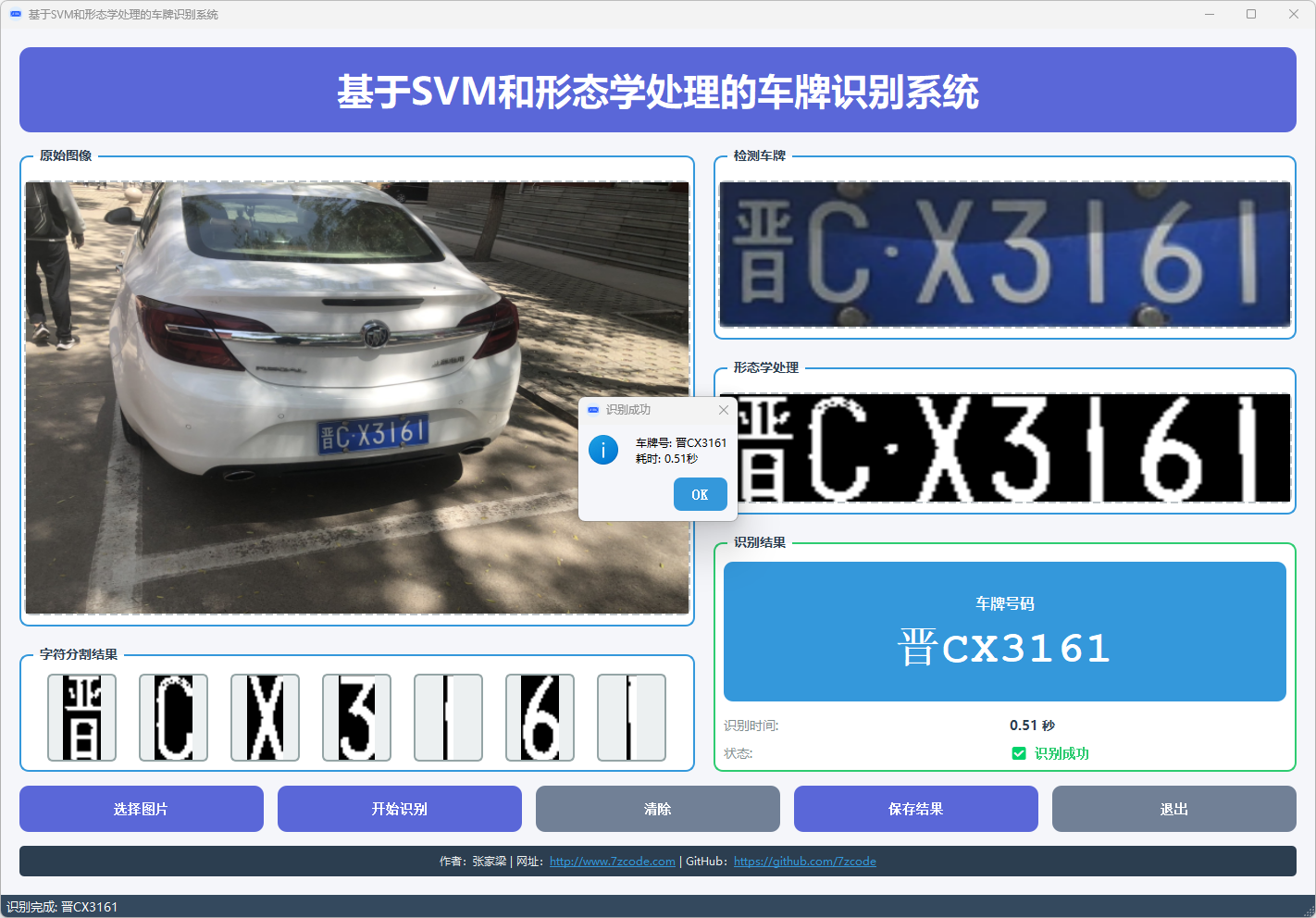
图9 车牌识别结果
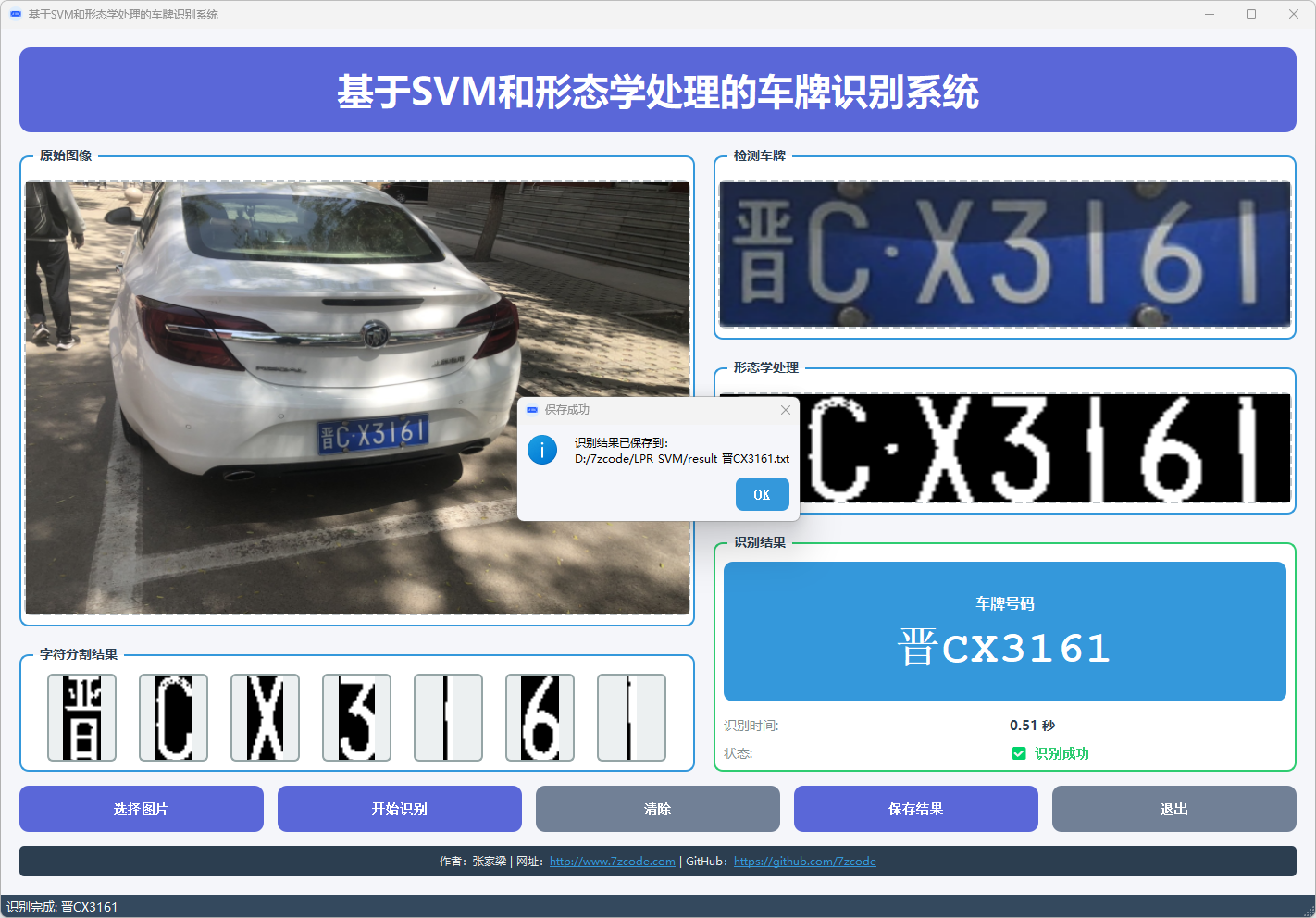
图10 车牌保存结果
项目资源
配套文档
点击查看:基于SVM和形态学处理的车牌识别系统 注意:免费提供!
配套文件
包括完整的项目源代码、演示视频、运行截图,开箱即用。

项目信息
作者信息
作者:Bob (张家梁)
项目编号:IP-5-P
原创声明:本项目为原创作品
联系方式
开源协议
本项目采用AGPL-3.0开源协议,允许个人和组织自由使用、修改和分发代码,但基于本项目的衍生作品必须同样开源,且用于提供网络服务时需向用户提供完整源代码。本项目仅供学习研究使用,作者不对使用本项目产生的任何后果承担责任,使用者应遵守当地法律法规,合理合法使用本项目。如本项目对您的研究或工作有所帮助,欢迎引用并注明出处。
评论(0)