

Abstract:This dataset adopts the YOLO annotation format and contains 1,420 tomato images. It is divided into training, validation, and test sets at a ratio of 7:2:1. The dataset is used for training and evaluating tomato ripeness detection models for four categories: unripe, turning, semi-ripe, and ripe.
Dataset Introduction
Dataset Overview
This paper constructs a self-built dataset for intelligent tomato ripeness detection. The dataset adopts the YOLO object detection annotation format and is mainly designed for tomato ripeness recognition and localization tasks. It contains a total of 1,420 tomato images. The images cover tomato targets under different lighting conditions, angles, backgrounds, and ripeness states, which can effectively reflect complex detection environments in real agricultural scenarios.
According to tomato color and growth status, the ripeness levels are divided into four categories: unripe, turning, semi-ripe, and ripe. Bounding box annotations are provided for tomato targets in each image.
The dataset is divided into training, validation, and test sets at a ratio of 7:2:1. The training set contains 993 images, accounting for 70%; the validation set contains 284 images, accounting for 20%; and the test set contains 143 images, accounting for 10%. Each image is paired with a corresponding .txt annotation file. The annotation content includes the class ID, target center coordinates, width, and height. All coordinates are normalized, meeting the training requirements of the YOLO model.
This dataset can be used for the training, validation, and testing of YOLOv8-based tomato ripeness detection models. It provides data support for intelligent tomato harvesting, automatic sorting, and agricultural visual detection systems.
Dataset Source
The tomato ripeness detection dataset used in this study is a self-built dataset. The images are mainly collected from greenhouses, plastic greenhouses, and natural planting environments. They are manually annotated and organized according to the YOLO object detection format for model training, validation, and testing.
Dataset Size and Split
- Total number of images:1,420;Total number of annotated bounding boxes:11,158
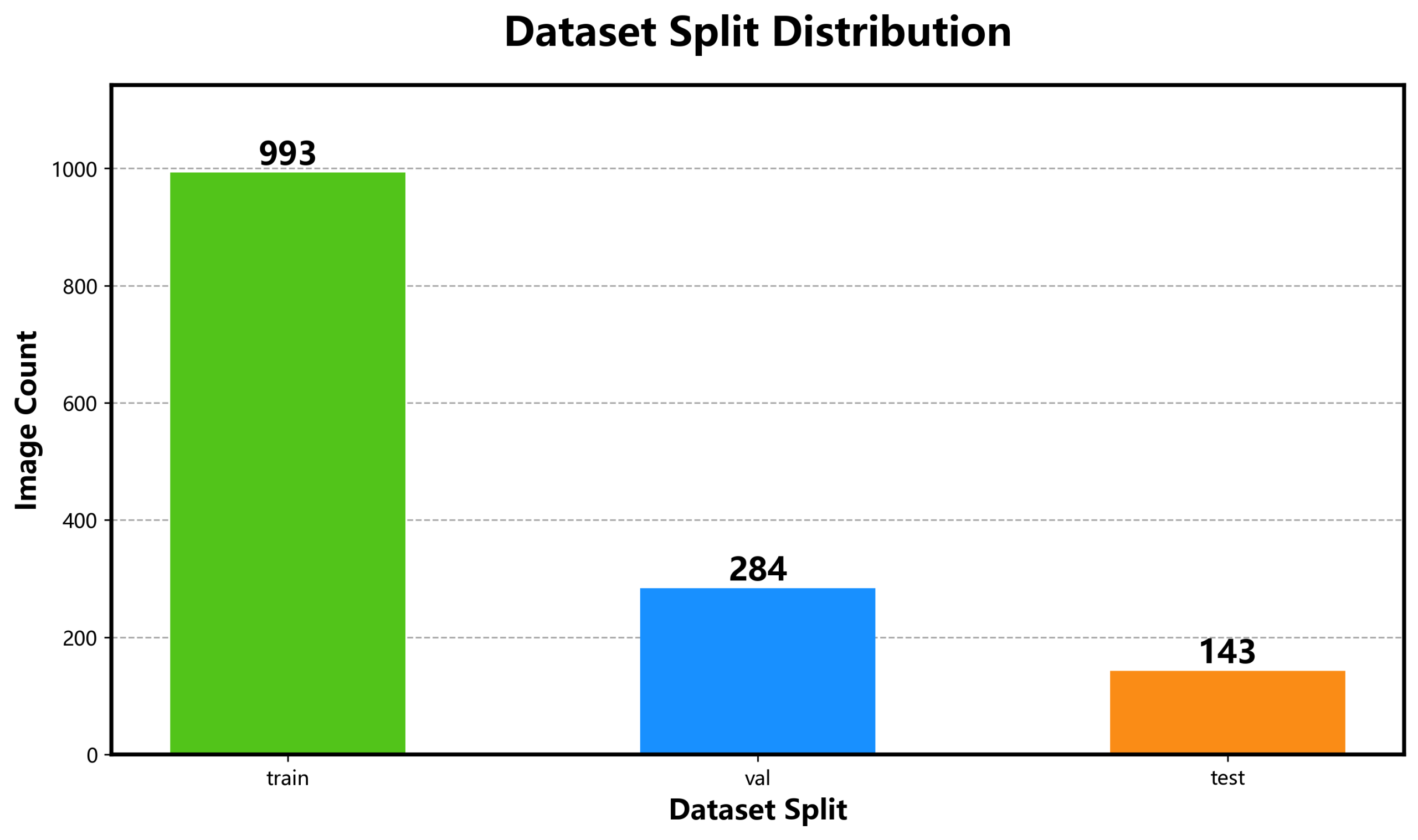
Figure 1 dataset_distribution-scaled
Quality Control
The annotation process adopts a two-stage quality control procedure. First, standardized annotation and self-checking are performed to ensure that each bounding box closely fits the external rectangle of the target instance and that the class labels are consistent. Then, sampling review is conducted to correct missing labels, incorrect labels, and bounding box position deviations. Disputed samples are checked again to improve inter-annotator consistency and overall annotation reliability.
Data Format and Usage
The dataset is organized in the standard YOLO format and can be quickly integrated into the training process through the data.yaml configuration file.
Directory Structure
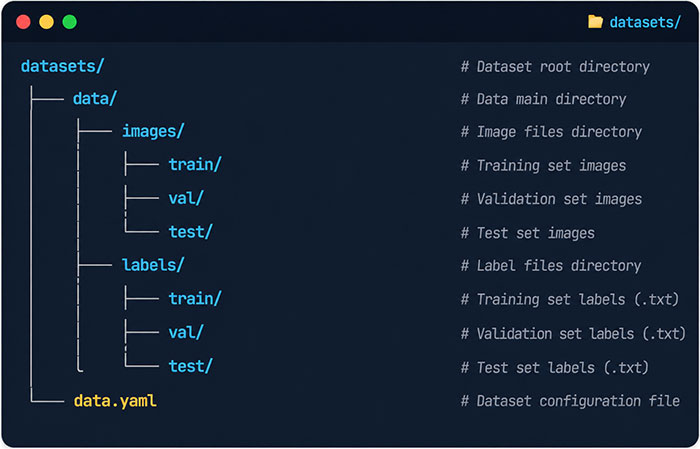
The dataset is organized in the standard YOLO format. Image files and annotation files are stored separately in the images/ and labels/ directories, and are divided into training, validation, and test sets.
Performance Evaluation
result
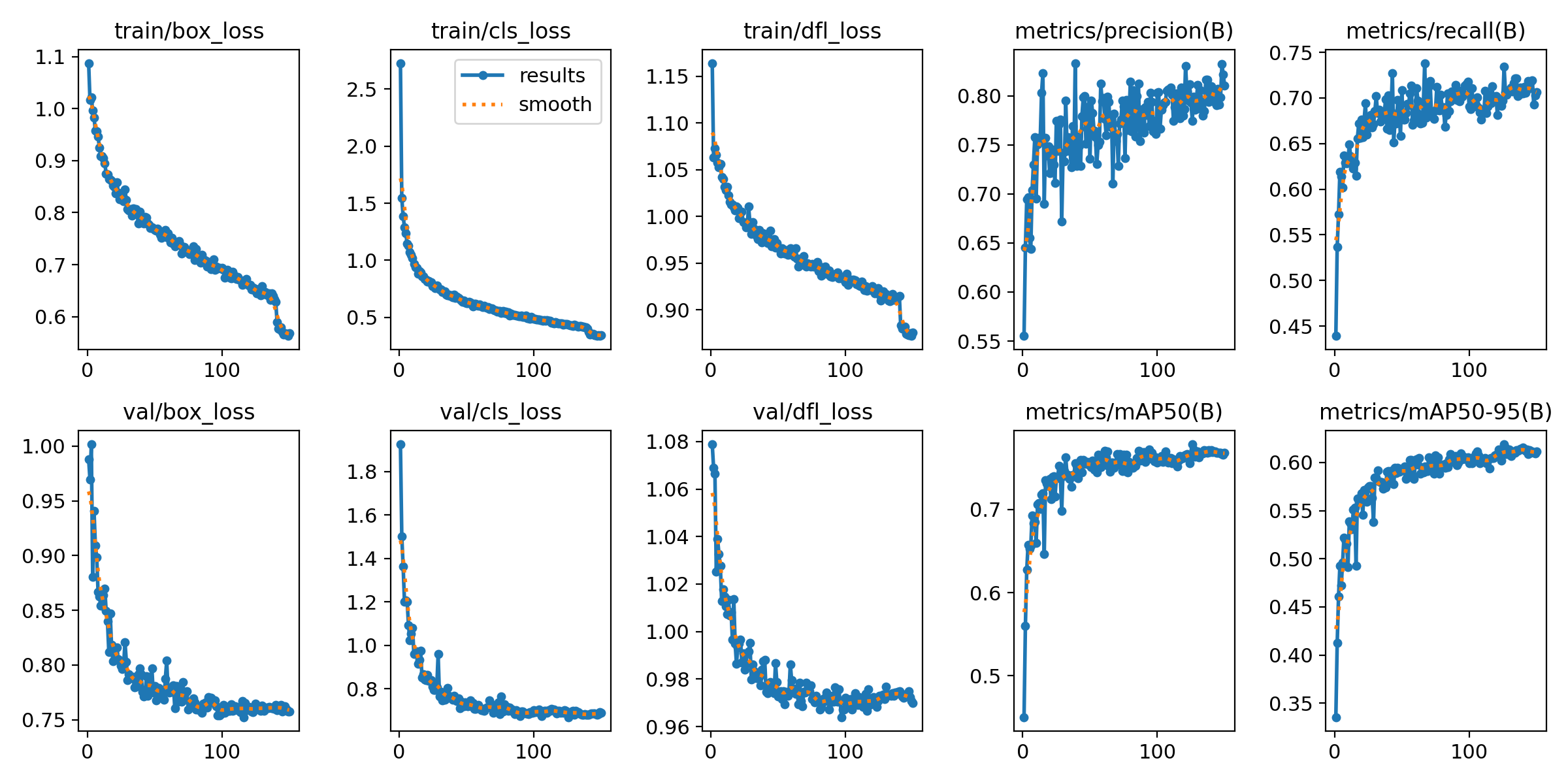
Figure 2 results
BoxPR_curve
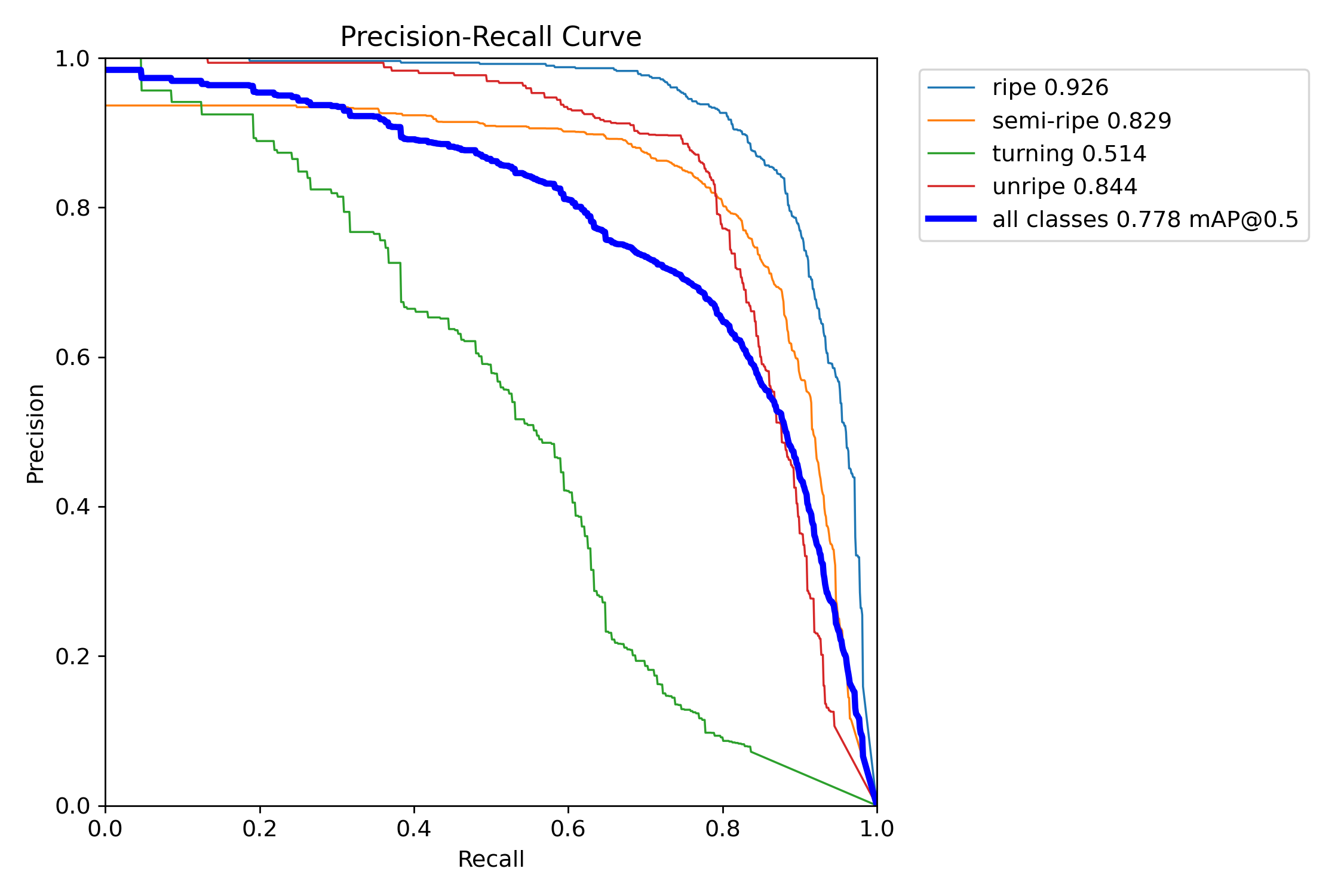
Figure 3 BoxPR_curve
confusion_matrix-scaled
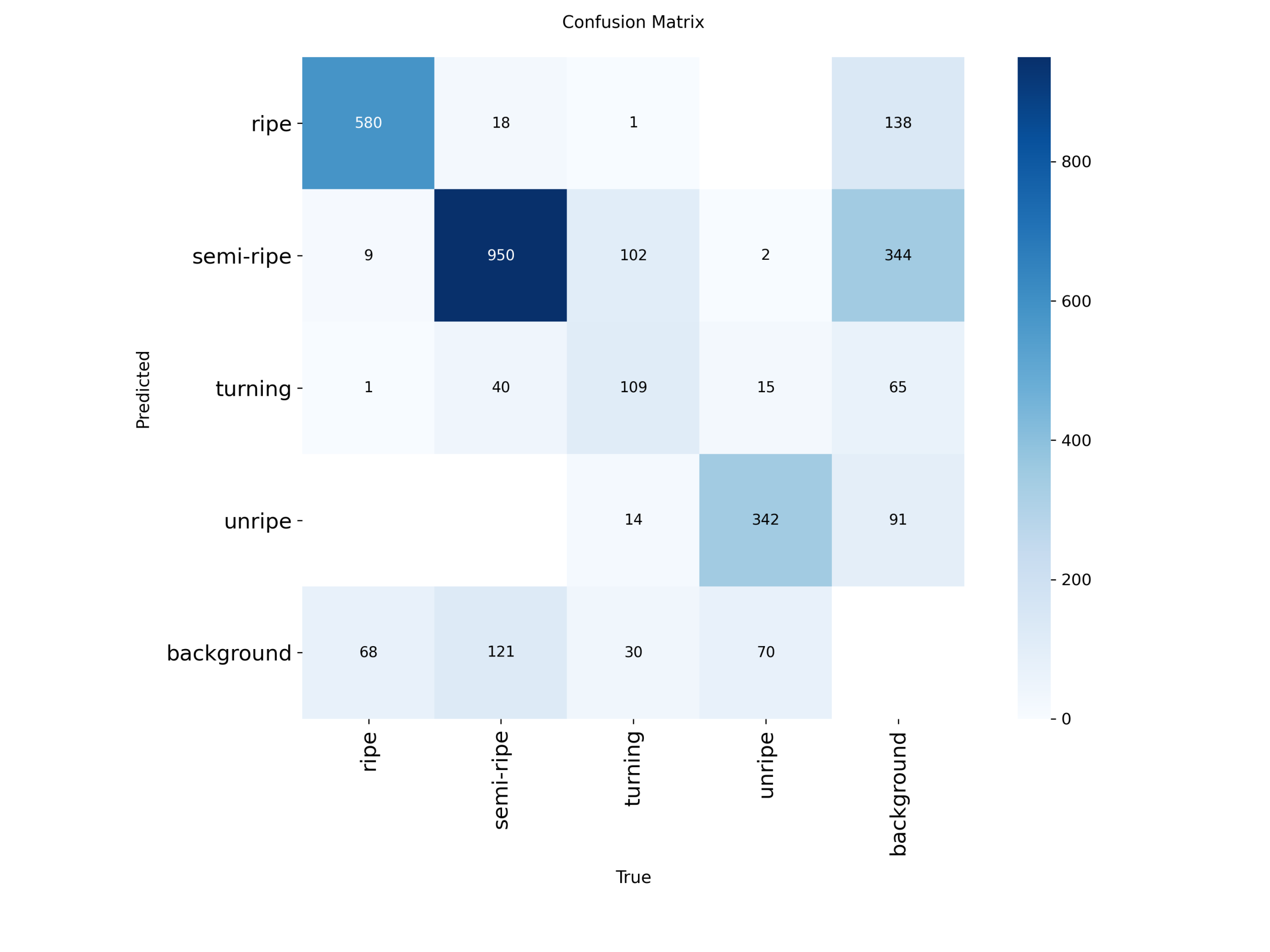
Figure 4 confusion_matrix-scaled(person / leaflet)
Application Case

Figure 5 Intelligent Tomato Ripeness Detection System Based on YOLOv8 Deep Learning
Dataset Information
Disclaimer and Citation
The data is intended for research and educational purposes only. If it is used in commercial scenarios, please verify the data license by yourself. If you need to cite this dataset, please indicate the dataset name and version number in your paper or report.
Author Information
Author: Bob (Zhang Jialiang)
Project ID: AI-1-Datasets
Originality Statement: This dataset is an original work.
Contact Information
Email: wesharecode2023@gmail.com
GitHub:https://github.com/7zcode
YouTube:https://www.youtube.com/@7zcode
Open Source License
This project is licensed under the AGPL-3.0 License. You may use, modify, and distribute the code, but derivative works must also remain open source under the same license. If the project is used to provide network services, the complete source code must be made available to users.
This project is for learning and research purposes only. Users are responsible for complying with local laws and regulations. If this project is helpful, citation and attribution are appreciated.
评论(0)